As you can imagine as an engineer and someone who has a Masters degree in Artificial Intelligence I am super excited that AI is finally in a everyday usable state. There are many use cases for AI that I absolutely love – programming my home automation system has become better with the help of Copilot, navigating my large inbox is better with Copilot and my powerpoint presentations have much better graphics nowadays thanks to ChatGPT. It also has some downsides – one being that my son thinks my job is to create Star Wars memes for work (which made my practice townhalls a lot more entertaining). On a serious note there are several cases where AI gets it wrong and I have not found Vibe Coding to be good enough for my use cases yet, not to speak of the large amount of not useful content that is flooding my LinkedIn feed, my email inbox and any even my txt messages.
What this has shown me is that AI will really influence how we work and how we communicate and I was wondering what will we do with all the productivity we will unlock? And then remembered that all too often we don’t really use the productivity well. And I want to use a warning analogy.
Come with me into the past – It is the 1970s and we are at a business conference. I stand on stage and am pitching the next “big thing”. And here comes my pitch – There is this new technology that will create incredible productivity for you. I know many of you are sending documentation to other people in your organisation via mail or tube mail or if it needs to be very fast with a fax machine. The quality and cost of the fax machine is obviously quite limiting. Well with this new technology you will be instantantiously be able to send information at high quality for basically free to anyone anywhere. Can you imagine the productivity improvements we will see from that?!?
Of course I am talking about email which still had to go some way to live up to that promise over the next couple of decades, but the pitch and promise came true. You can send the information at high quality and basically for free and if I take email (and any equivalent capability) away from you, your productivity will drop. But ask yourself whether you feel like email is making you more productive. Or have we found ways to “eat up” that productivity by increasing the volume of emails to the point with low value information? The boat has sailed on email I think – the ongoing war of spam vs spam filters, the intentions to use less email vs the learned behaviour of checking it all the time – all this indicates that the brave new world I pitched in the paragraph above will not come of fruition.
The question I am asking myself is whether or not we will make the same mistakes with AI or whether we will find ways to truly unlock the productivity. I have spent hours with Copilot creating code for me that I could have probably written as fast myself. How can organisations focus on the productive use cases of AI and avoid the pitfalls? I don’t have an answer for this yet, but being conscious of our tendency to “eat up” the productivity that technology creates is a useful first step.
How do we measure the productivity of developers? This is a riddle that I have been working on for a while (see this post). And how do we measure transformation success in the same context?
If we had good answers to these two questions things would become a lot easier for us in the DevOps community. At the DevOps Enterprise Summit 2022 I had many great conversations in the hallway track to get different perspectives (special mention to Hans Dockter and Bill Bensing for entertaining a good discussion amongst many others), which allowed me to get some clarity in my head. I will share where I got to with you all in this post, which might be a bit on the longer side.
Developer productivity is extremely difficult to measure; lines of code, story points, etc all fail to really measure it. But what many people can align on is that you can measure toil – the work that does not add value in the SDLC. One good measure for toil is the transaction cost of code (see more on that here) – one proxy way to measure this is the time between the code commit and the deployment and validation in production. So if we speed up this feedback cycle we can use that as a first-order proxy for the transaction cost. Let’s use this for this article.
The goal of Transformation is to achieve optimal Transaction cost
One major goal of any DevOps transformation is to improve developer productivity and remove toil. This will speed up the delivery cycle and as a result, likely reduce cost. If we keep or improve quality standards along the way we are scoring some major goals for the organisation.
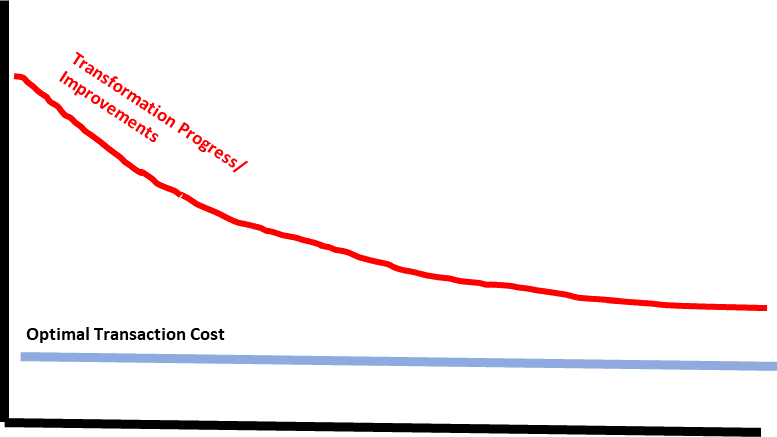
The optimal transaction cost is a theoretical construct – it represents the minimum possible time and effort it could take to deploy and validate code in production. All the manual steps like manual testing, approvals, deployments, and infrastructure changes increase the cost above the minimum transaction cost. Automated but not optimised steps like unnecessary scans or build processes also increase the transaction cost. You can assume that we will never achieve the optimal transaction cost as the incremental cost to improve transaction costs further become uneconomic at some stage. Transaction cost improvements as part of transformations usually follow an asymptotic curve – or the law of diminishing returns.
Optimal Transaction Cost is a function of architecture and process/governance
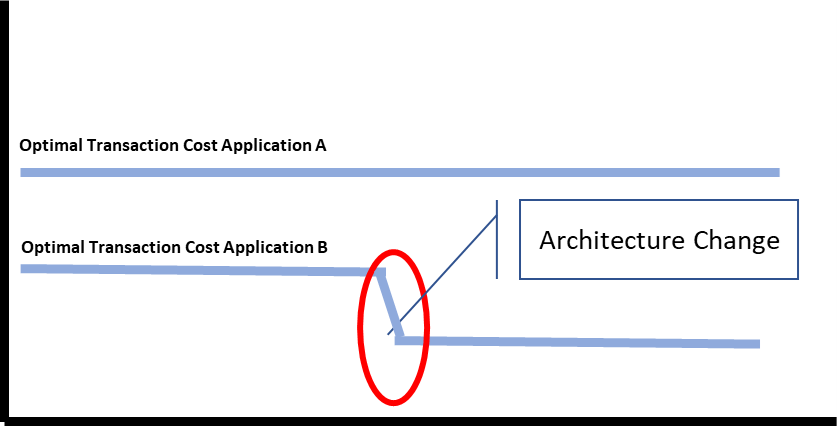
So what determines the optimal transaction cost for an organisation. Well first of all the optimal transaction cost is not determined organisation wide. The technologies in use and the architecture are factors that differ across teams in an organisation. It’s easy enough to see if you think that a packaged software application likely compiles in minutes, a custom app in seconds, and serverless functions not at all. Clearly, this will make a difference in the transaction cost that we can achieve. But it is not technology and architecture alone that determines the optimal transaction cost per application. The processes and governance in place across the organisation will play the other major role in determining the optimal transaction cost you can achieve as a team.
You might notice that I consider architecture and governance/process as static in the calculation of optimal transaction cost. I do this because I believe transformations to be first and foremost something that teams drive – if you saw my talk at DOES 2022 I speak about the “choose your own adventure DevOps transformations” of teams that you need to guide if you want to transform whole organisations. I will talk about how to elevate the game across the organisation in the next section. But before I do that let’s look at what team-driven transformations then look like.
This graph shows two applications one being a larger packaged software, and the other being a smaller custom application. The optimal transaction costs are different as mentioned.
Here you can see how each team is making progress. It’s not linear, and it’s not always making it better, but overall the teams are getting closer to the optimal transaction cost. As I said before it’s not expected for them to ever achieve it and there are other things they are improving along the way too (like quality standards or effectiveness of business experiments).
Transformation progress is achieved through 3 attack angles
Now that we have done the groundwork, let’s talk about the business of transformation. With all this in mind, we can better explain what we are trying to achieve and how to measure it. Let’s assume we found a way to measure transaction costs by either implementing some kind of delivery telemetry or by using a less tool-focused approach like value stream mapping. We then have three different “attack angles” for our transformation:
Achieve optimal transaction cost through automation and streamlining
Improve optimal transaction cost by changing the process/governance across the portfolio
Improve optimal transaction cost by changing the architecture
Let’s go through them in more detail.
Achieve optimal transaction cost through automation and streamlining
This is the team-level transformation where much of the transformation energy needs to be. Teams need to look at their context (perhaps create a value stream map) and identify two things: The areas they can improve themselves and the higher-order constraints that need to be solved outside their team. And then they need to get on with the first while making sure that the second is appropriately prioritised at the organisational level. At this level, we will increase test automation, build infrastructure automation and improve the deployment process among other things. This is very much what I showed in the earlier graph.
Improve optimal transaction cost by changing the process/governance across the portfolio
Even if everything is fully automated there is still a process of governance to go through – often “hoops” and “red tape” can materially add to the transaction cost and need to be reviewed to see what still adds value and what is “toil”. Given process and governance is usually company-wide, the process cannot be optimised for each application. This means that even if there is a multi-speed model (and there should be if you followed the logic of this post), each speed will still have to cater to the slowest mover in the category. As application uplift their capability, the process and governance need to evolve at the same time. But changes to the governance process can improve the optimal transaction for many applications making it a very powerful but difficult change.
Improve optimal transaction cost by changing the architecture
The optimal transaction cost for a specific technology is determined by the level of automation and the achievable speed – as mentioned this is different for example for a small custom app vs a large packaged application. The level of dependencies in the architecture will be another determining factor. So how can we push ourselves to the next level? By changing the architecture – either through decoupling or by transitioning to a different technology. Once you change to a new transaction cost level, there might be new things to do regarding automation and streamlining processes, and new options regarding process and governance might become possible. From here on in it is in progressive iterations that progress is made.
Interactions between 2 and 3 – it’s an iterative process
I think it is obvious that these three attack angles happen in all permutations, parrel or sequential and once you have made improvements along one of those angles new opportunities arise along another. So you need to keep working on your transformation at both the team and organisational level and use a transformation “compass” like a balanced scorecard (see more below and here) or other guidance to keep pushing the transformation forward. Just keep in mind that you need to have an economic framework to guide you – at some stage before you reach the ideal transaction cost you will likely encounter a plateau from which there is no economically sensible next step. Don’t worry – this will change again in no time as the environment around you changes and new opportunities and challenges arise. Personally, I have encountered such plateaus at the team level but never at the organisational level, there is always something beneficial to improve.
When I talk about transformation I usually use a balanced scorecard approach and clearly the perspective described in this post predominantly sits in the development efficiency quadrant. It is a very important quadrant but not the only dimension you want to cover in your transformation. I will explore the other quadrants in due time in other blog posts.
In the past, we treated testing or quality assurance in IT delivery as something akin to insurance. We test as much scope as possible in traditional waterfall delivery before releasing it into production so that the testing team can “assure” quality. If something goes wrong, the fault lies with the assurance gone wrong. From a delivery team perspective, we put the fault at the feet of the testing team, and after all that is why we paid for their service. In case there is another vendor involved for testing we could even blame the cost of poor quality on that vendor as “clearly” they should have found it during testing. So the cost of testing could be seen as the insurance premium paid by the delivery team so that when something goes wrong we can call on that insurance to put the cost at the feet of the testers.
The world has materially changed and IT delivery works with different paradigms now. I had some fascinating conversations over the last few months that showed me how testing and quality engineering are following a different paradigm now. It is economic risk management. Let me explain what I have learned.
Let’s start with the scenario. Assume we can identify the whole scope of an application, all the features, all the logical paths through the application, and all the customer/product/process permutation. That will give us 100% of the theoretically testable scope. If you accept 100% risk, you could go live without any testing…well you wouldn’t, but theoretically that would just be maximum risk acceptance. So how do you define the right level of testing then?
Here is the thought process:
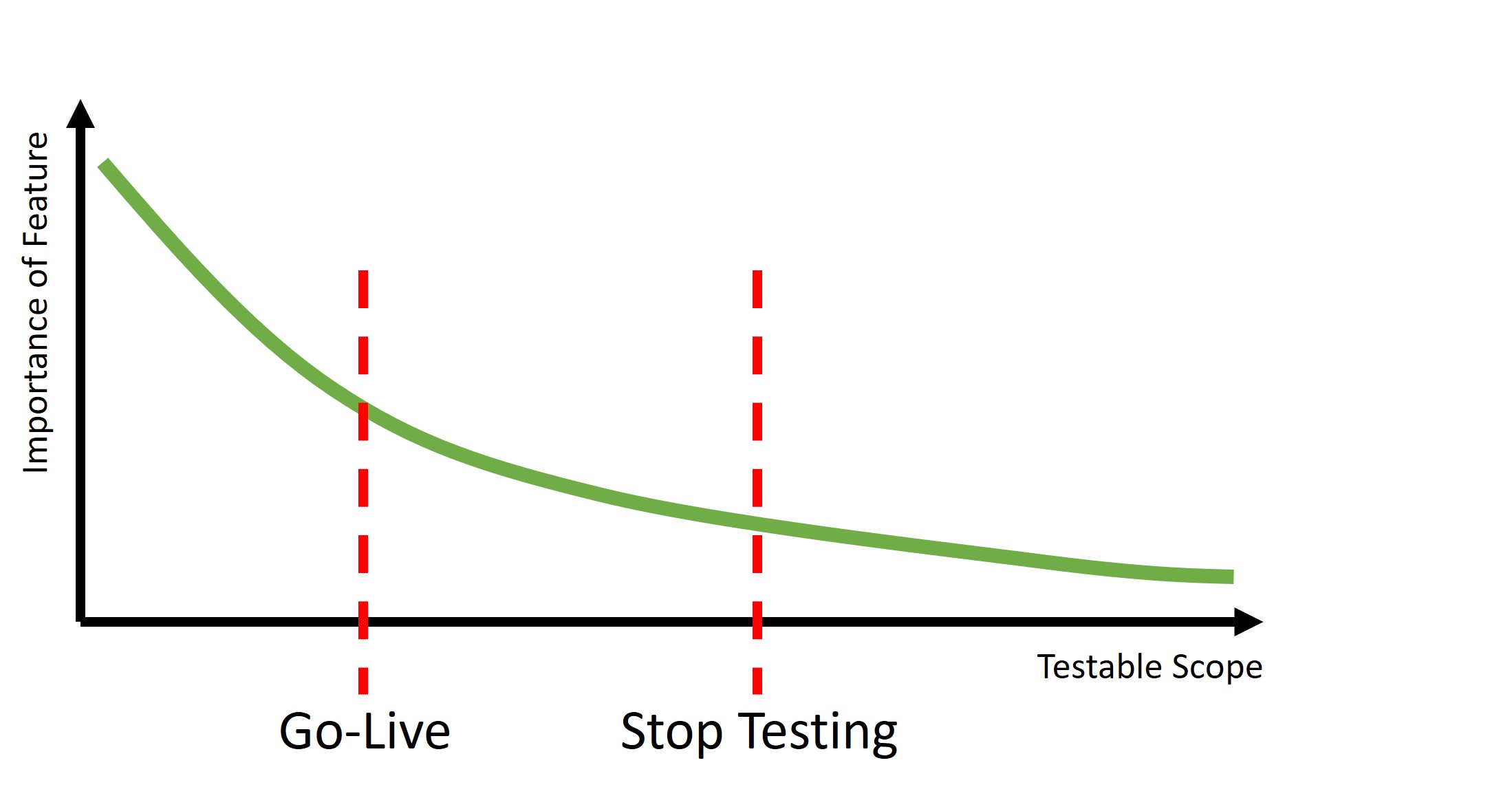
Let’s assume we can align all the testable scope from most important to least important (by business criticality, customer value, or whatever else is the right criteria for your company). You can then define two critical points on that continuum:
The point at which you have done enough testing that the risk of go-live is acceptable
The point at which the cost of further testing is higher than the value associated with the remaining tests -> e.g. the point at which we should stop testing
You might notice that the two points are not the same, which means testing does not have to stop at Go-Live. The idea of continuing testing after the release is not new. Some companies have always used production for some testing that wasn’t possible in non-production environments.
What we are saying here is that you might decide to go live due to the business benefits, but that you will continue testing in parallel with stakeholders using the application in production to flush out lower-risk problems. The idea is that if a user beats us to find a problem that the impact is acceptable. Less frequently used features or lower-value features might qualify here for post-go-live testing, you wouldn’t want to hold back high-value features from going live if an untested feature is unlikely to be used in production before we get to test it.
There are two thoughts here that would have been heresy when I started testing nearly 20 years ago:
You can plan to go live before you complete testing
Testing continues after go-live to find defects faster than the user does
In Agile training, we speak about the need to prioritise defect work with features; making the choice of allowing a defect to exist longer if I have higher value features to be delivered. The way I describe testing in this blog is following the same thought process. We want to maximise value and economically evaluate our options.
I am excited by this economic testing framework and encouraged by some of the conversations I have been able to have in support of this idea. People have inherently used similar ideas when they ran behind on testing or when fix-forward decisions were made. Formalising this thought process and consciously planning with it will create additional value for organisations.
The implications are clear to me: Testing has moved from being a phase to being an ongoing endeavor. Given the limited capacity, prioritisation calls need to be made ongoingly on where to invest the capacity; in the pre-release phase or in the post-release phase, on further testing existing features or on testing newly created one, more testing on high-value features or doing a first round of testing on lower-value features. An economic model based on risk should drive this, not the need to achieve a certain test coverage across the board. What testing strategy we follow should be conscious business decision, not an IT delivery decision.
I am sure you will hear more about this modern take on testing and risk management in the future.
The first post-pandemic DevOps Enterprise Summit. I am sorry I doubted you DOES, thinking now that I nearly gave it a pass feels crazy given how much positive energy, great ideas, and inspiring stories I was able to take away from the conference.
So here come my reflections on what I saw this year:
Themes:
Unavoidably Covid, the economic outlook, and the situation in Ukraine were a constant backdrop to the stories and shows how organisations weathered the storm
The hallway track and exhibition hall was full of discussions about Developer Experience, Developer platforms, and Developer productivity (and some consensus that you cannot measure productivity easily, but you can measure the reduction of toil as a proxy)
On stage the themes were:
Bringing business and IT together
Automated governance and making audits less painful
The support of expert teams, platform teams, (and whatever else you call it) that can help your DevOps journey
Top 3 talks:
Transformed! A Musical DevOps Journey with Forrest Brazeal
What a performance – I cannot wait to share the video once available. The songs were funny and heartfelt, the appeal in the middle was close to my heart and he had the whole audience captive for his session. Thanks, Forrest, I hope you go viral! Check it out here.
adidas: How Software Engineering Boosts the Next Adidas Commerce Transformation
A smashing video that showed the Tech behind Adidas, a presentation showing how Adidas innovated at a fast pace and the incredible scale Fernando deals with. A couple of interesting takeaways:
Each of his technology hubs owns a technical capability, which made each hub a priority in its own right and less focus back on HQ
The incredible economic impact outages can have (1M per hour at peak)
What incredible fun it can be to solve problems when you are close to your customers
Simplification and Slowification: Creating Conditions for the Enterprise’s Distributed Intelligence to Achieve Unparalleled Results
A powerful analogy about painting rooms and moving furniture. The ideas of simplification and slowification will need to sit with me for a little while before I fully get my head around them. Some great sound bits – “Winners harvest the intellectual horsepower of their organisation”. As a leader you need to shape the time and space of your people, so that can solve problems when they are not under high pressure and can operate safely later. You can read a bit more about the analogy here
A quick flyby of some of the other amazing talks:
Do I Need to Insource to Achieve My DevOps Goals?
An appeal to figure out how to work with Global SIs given they make up a large part of the industry. Not very surprising that I felt spoken to. And a great re-iteration from Gene upfront that the DevOps survey found that it is not outsourcing that is a problem for DevOps, it’s functional outsourcing that creates barriers that is the problem.
Airbnb’s Nimble Evolution: Chapter One How Airbnb is Evolving Its Ways of Working
A nice view of the early steps, the first chapter, of Airbnb’s evolution with a key takeaway being the problem of having too much WIP to be successful
2×2: Organizing for DevOps Success in Large Bureaucracy
The 2×2 matrix of unity of command vs proximity to customer outcomes will become a staple in my client discussions. So simple, so powerful
Dear Security, Compliance, and Auditors, We’re Sorry. Love, DevOps.
A really interesting view under the hood of automated governance. Lots of interesting things to take away and try out.
Creating the Value Flywheel Effect
Lots to digest in this one about cloud migrations and serverless – I also liked the term “legacy cloud” for apps migrated but not transformed.
Automated Governance Changed What We Believed In
This one hit close – the story about automated governance showing how a team didn’t follow a corporate standard which could have been cause for dismissal gave me a perspective that I hadn’t had before. Really worth considering when speaking about psychological safety.
Operational Excellence in April Fools’ Pranks: Being Funny Is Serious Work!
Fun presentation by Tom and then it ended up also being insightful about the need and power of good operational controls and feature flags. A talk worth a rewatch.
Human Complications (and Complicated Humans) in Digital Transformation
Very insightful talk about success in digital transformations. I especially liked the idea that products are the software-tised versions of the business. Honesty and alignment as core tenants for success resonated with me as well.
CSG: CSG’s Ongoing Transformation Story
The quote “Leadership looks a lot like loving people” was such an interesting aspect that I am still thinking about how appropriate or inappropriate the analogy is.
Disney: Disney Global SRE – Creating Digital Magic
Another Jason Cox masterpiece with plenty of Star Wars imagery – I still think Jedi Engineering Training Academy is super cool. How do I get a certification from that academy?!? The talk was powerful as it gave good advice on how a shared service can be successful: In summary: Actually help your customers
Lessons Learned in Engineering Leadership
A humbling story from Michael Winslow who made the journey back from management to individual contributor. A story told with lots of feeling. All the best for your next step Michael.
And then the last talk blew it all out of the water…
Right Fit, Wrong Fit – Why How You Work Matters More Than What You Value by Andre Martin
He spoke about the importance of fit that a person needs to have with the company they work in. People referred to it as a TED talk and that is absolutely correct. I cannot wait for his book to come out next year. The advice to really get to know yourself and your values (not the values you want to have, but the ones you do) and how incredibly impactful the right fit is inspired me. I have to share this talk with many people I know. Thank you Andre.
I could have listed a dozen more here – It was a great event and the whole DevOps community was beaming just for being back together. And the talks gave us all things to take back to our organisations and we made new friends along the way. Looking forward to DevOps Enterprise Summit 2023 already.
This week is the big family re-union of the DevOps family at the DevOps Enterprise Summit 2022 in Las Vegas. I was lucky enough to be invited back as a speaker and was preparing my talk about DevOps Heresy – things I do that break the “common” rules of DevOps when I realised I cannot squeeze it all into my allocated time.
In my talk I speak about things that might surprise you about some of my teams. I would have called these DevOps Heresy myself a few years ago ( … and I am looking over my shoulder wondering whether the “DevOps police” is turning up any minute)
– The team did not fail pipelines with failed tests
– The team did deploy code that had failed security scans
– The team chose manual cloud deployments over automation
– The team moved from Full Stack to a federated model
I have learned so much from working in large complex enterprises over the last few years that I wanted to share it all in one talk – and of course I realise there is not enough time to cover it all.
Hence I feel I have no choice but to write a series of blog posts that go deeper into the world of DevOps heresy and why I think context is king.
My talk finishes with the unsolved riddle of how to find the right balance between pragmatic progress and evangelism that pushes the boundary. This is the real trick of any large-scale transformation I find. I will remain a pragmatic evangelist of DevOps. Looking forward to sharing a few steps of my recent journey with the community.
Phew – finally I am sitting down to write this post. Nearly 2 years since I wrote my last blog post and I have missed this. It’s my birthday and this is as good a day as any to re-energise my blogging.
Let’s be honest the last 2 years were hard for everyone, I didn’t feel like reading or writing about DevOps when my podcast listening list was full of Corona podcasts instead of DevOps and Agile, when I was following the case and vaccination numbers like I normally follow football scores from the Bundesliga and when the idea of speaking at a conference meant to sit at home in front of a camera. Now I think the tide has turned and I am honestly ready to crawl out from under the Corona rock.
Both in my professional and private life there was lots of interesting stuff happening and I came through the last 2 years with my sanity and health mostly intact (well trying to work from home as two working parents with no childcare meant sanity got a new definition around my house…)
So what to expect from me – well I set myself the goal to post once a month to ease back into it. My topics will include the usual Agile and DevOps topics but given I spent more time with cloud migrations you might see a few of those posts too. And indeed the next post will be my reflections on the state of cloud migrations, which I will hopefully get out next week.
I am looking forward to reengage with the DevOps and Agile community and to hopefully meet many of you again in person at a conference in the hallway track or just in a bar over a scotch. Here is to hoping 2022 is a step back to writing and putting my thinking into this blog format.
And on a sidenote I am writing a utility to optimise my solar system by using the battery in my Tesla M3 in the best way – I started to write up what I am doing in a separate blog. If you follow me on twitter I will share what I am doing once I have put it in a shareable format.
Okay this blog post will be less pragmatic than my usual ones, but I need to get this off my chest. Why do I encounter so many Agilists that are less agile in mind than many of the PMs I know who work on Waterfall projects? Does any of this sound familiar to you and drive you as mad as it does me:
“This is not true Agile”
“This is not called a User Story it’s a PBI (or vice versa)”
“Method X is not Agile, Method Y is much more agile”
“Sprints need to be x days long and not any longer”
I have even heard that some methodologies prevent people with their highest trainer certifications from being certified in other methods. I cannot confirm this, but if true it is madness in my view.
This reminds me of all the passion and silliness of this scene from Monthy Python’s Life of Brian:
Let’s make one thing clear: There is no award for being Agile according to any one Agile method. This level of dogma is completely unnecessary and is taking too much energy in Agile discussions.
What we are trying to do is deliver better solutions faster. And all the methods and tools out there are for us to combine to achieve that. Of course when you are not mature you should follow one of the methods more strictly to get used to the new way of working and then later combine it with other elements (Shu Ha Ri is a common concept we use to explain this). We should focus on that. I appreciate that it is often harder to measure outcomes than compliance to a specific method, but it’s worth it.
So if you encounter an Agile coach that is dogmatic or only follows one method and speaks disrespectful of all others, be careful. He might be able to help you a few steps of the journey, but you should look for someone more open minded to help you in the long term.
There are a lot of good talks/articles out there that challenge our “folklore” of software delivery, I find it extremely interesting to read about people who diverge from the “scripture” and do research to prove or disprove what we think we know. A couple of examples:
I have been speaking over the last couple of years about the nature of DevOps and Agile transformations. It is in my view not possible to manage them with a simple As-Is To-Be approach as your knowledge of your As-Is situation is usually incomplete and the possible To-Be state keeps evolving. You will need to be flexible in your approach and need to use agile concepts. For successful Agility you need to know what your success measures are, so that you see whether your latest release has made progress or not (BTW something way too many Agile efforts forget). So what could these success measures look like for your transformation?
Well there is not one metric, but I feel we can come up with a pretty good balanced scorecard. There are 4 high level areas we are trying to improve: Business, Delivery, Operations and Architecture. Let’s double click on each:
Business: We are trying to build better solutions for our business and we know we can only do this through experimentation with new features and better insights. So what measures can we use to show that we are getting better at it.
Delivery: We want to streamline our delivery and get faster. To do that we will automate and simplify the process wherever possible.
Operations: The idea has moved from control to react, as operations deals with a more and more complex architecture. So we should measure our ability to react quickly and effectively.
Architecture: Many businesses are struggling with their highly monolithic architectures or with their legacy platforms. Large scale replacements are expensive, so evolution is preferred. We need some measures to show our progress in that evolution.
With that in mind here is a sample scorecard design:
I think with these 4 areas we can drive and govern a transformation successfully. The actual metrics used will a) depend on the company you are working in and b) evolve over time as you find specific problems to solve. But having an eye on all 4 areas will make sure we are not forgetting anything important and we notice when we overoptimize in one area and something else drops.
Next time I get the chance I will use a scorecard like this, of course implemented in a dashboarding tool so that it’s real time. 😉
I have been working in agile ways for many years now and many things have become a mantra for every new engagement: we have teams of 7 +/- 2 people, doing 2 weeks sprints and keep the teams persistent for the duration of the engagement. Sounds right, doesn’t it? But is it?
How do we know those things? Do we have science or do we just believe it based on the Agile books we have read and what people have told us? Over the last few weeks and months I have actively sought out differing opinions and research to challenge my thinking. I want to share some of this with you.
Team size
Agile teams are 5-9 people. Full stop. Right? There is some research from Rally from a while back that shows that smaller teams are having higher productivity and throughput than larger teams. Larger teams however have higher quality. So far so non-controversial. If quality is really important we want slightly larger teams and a higher percentage of quality focused people in the team. What really made me rethink was an interview that I heard with an Agile coach, where he described how having larger teams lead to better predictability of outcome. He made two arguments for that, one was quality as discussed above where lower quality leads to rework and in small teams that can really hurt predictability. The second one was the more obvious one, in small teams sickness, holidays or other events have a much larger impact and/or people might feel less able to take time off and burn-out. So with all this in mind perhaps slightly larger teams are overall better, they might be less productive but provide higher quality, are more predictable and more sustainable. Perhaps those qualities are worth the trade-off?
Persistent teams
Teams should be long-lasting so that they only have to run through the Forming-Storming-Norming-Performing cycle once and then they are good to go. Every change to the team is a disruption that causes a performance dip. So far the common wisdom. I have heard arguments for a change in thinking – the real game changer is dedication to a team. Being 100% assigned to one team at a time is more important than having teams that work together for a long period of time. Rally in their research found that dedicated people have a 2x factor of performance while long-standing teams have only 1.5x. This model will also allow for more flexibility with scarce skillset – people with those can dedicate themselves to a new team each sprint. I feel there is something that speaks for this argument but personally there is a probably a balance to be found between full persistency and frequent change, but at least we don’t have to feel bad when the context requires us to change the team setup.
Sprint/Iteration Length
Shorter sprints are better. 2 weeks sprint are the norm. I have said those sentences many many times. When I looked at the rally research it showed similar to team size that shorter sprints are more productive but longer sprints have higher quality. So we need to consider this in designing the length of the sprints. We also need to consider the maturity of technology and our transaction cost to determine the right sprint length (less automation = longer sprints). And then I heard an interview with a German start-up. They run 2 week sprints most of the time, but then introduce longer 4-6 weeks sprints sometimes and the reason they give is that 2 weeks is too short for real innovation. Dang. Have we not all felt that the tyranny of the 2 week sprints makes it sometimes hard to achieve something bigger, when we forcefully broke up stories to fit into the 2 weeks or struggled to get software releasable in the 2 week sprint. I still think that the consistency of the 2 weeks sprints makes many things easier and more plan-able (or perhaps it’s my German sense for order 😉). But at least I will think more consciously about sprint length from now on.
There you have it, three things I took for granted have been challenged and I am more open minded about these now. As always if you know of more sources where I can learn more, please point me to it. I will keep a much more open mind about these three dimensions of setting up teams and will consider alternative options going forward.
This scene could be from a spy movie: Two people enter the room where release management is coordinated for a major release. The person from the operations team takes out a folded piece of paper, looks at it and types half of the password on the keyboard. Then the person from the development team does the same for the second half and then deployment to production begins. A couple of years ago I was working for a client, where the dev and ops teams had half the password each for production. It was probably the most severe segregation of duties setup I have experienced. The topic of segregation of duties comes up frequently when organisations moving towards using DevOps ways of working. After all how can you have segregation of duties when you are breaking down all the barriers and silos?!?
Let’s explore this together in this post, but first let’s acknowledge a few things: First and foremost, I am not an auditor or lawyer. The approaches below have been accepted to different degrees by organisations I have worked with. Secondly; there are several concerns related to segregation of duties. I will cover the three most common ones that I have encountered and hopefully the principles still can be applied to further aspects accordingly. Let’s dive in!
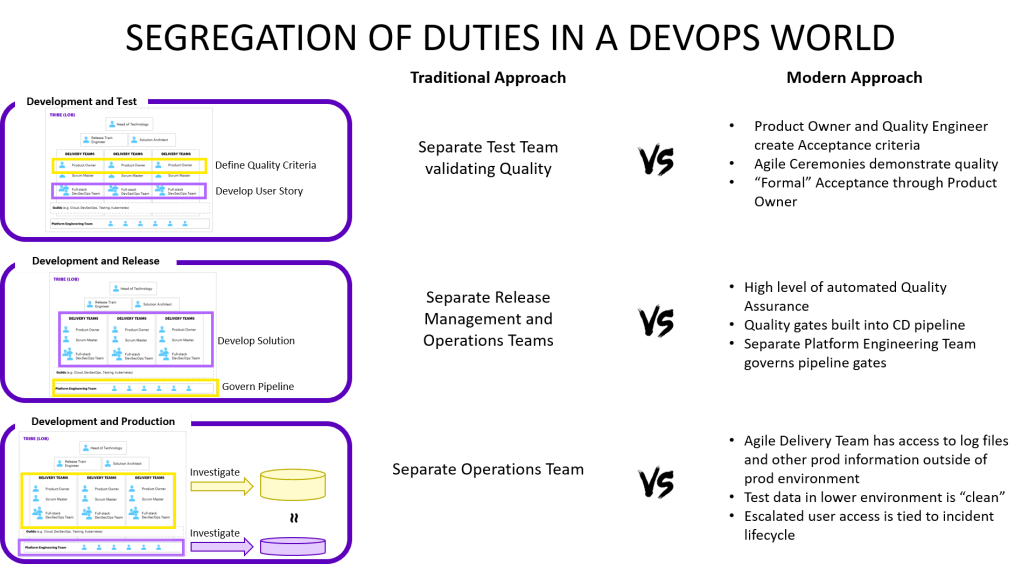
Segregation of Development and Test
Problem statement: In a cross-functional team wouldn’t the developer “mark his own homework” if testing is done by the same team?!? To avoid this in the traditional waterfall world, a separate testing team performs an “objective” quality control.
Resolution approach: Even in a DevOps or Agile delivery team, more than one person is involved in defining, developing and testing a piece of work. The product owner or her delegate helps define the acceptance criteria. A developer writes the code to fulfill those and a quality engineer writes test automation code to validate the acceptance criteria. Additionally, team members with specific skills like penetration testing or UX test the work as well. And often business users perform additional testing. Agile ceremonies like the sprint demo and the acceptance by the product owner create additional scrutiny by someone other than the developer. In summary, segregation of duties between Dev and Test is achieved as long as people are working well across the team.
Segregation of Development and Release
Problem Statement: A developer should not be able to release software into production without independent quality check to make sure no low quality or malicious software can be deployed. Traditional approaches have the operations or release management team validate quality through inspection and governance.
Resolution approach: In a DevOps world, the teams should be able to deploy to production automatically without any intervention by another team. This is true whether we use traditional continuous delivery or more modern cloud native deployment mechanisms. But how can we create segregation of duties in those release scenarios? We leverage high levels of automated quality controls in modern release mechanisms, which means functionality, security, performance and other aspects of the software are assessed automatically before software is deployed and we can leverage this to create independent assurance. A separate group like a “Platform Engineering” team governs the quality gates of the release mechanisms, the standards for it and the access to it. This team functions as the independent assurance and all changes to the release pipeline are audited. The art here is to get the balance right so that the teams can work independently without relying on the Platform Engineering team for day-to-day changes to the quality gates, while still making sure that the quality gates are effective.
Segregation of Development and Production
Problem Statement: A developer should not be able to make changes to production or see confidential data from production, while a production engineer shouldn’t be able to use his knowledge of production to deploy malicious code that can cause harm. Traditionally access to production and non-production systems are only given to mutually exclusive development and operations teams.
Resolution approach: This is the most complicated of the three scenarios as people should get the best possible data to resolve issues, yet we want to avoid proliferation of confidential data that can lead to exploitation of such data. The mechanisms here are very contextual but the principles are similar across organisations. Give the developers access to “clean” data and logs through a mechanism that masks data. When the masked data is insufficient for analysis and resolution, then escalated access should be provided based on the incident that needs to be resolved. Automated access systems can tie the temporary access escalation to the ticket and remove it automatically once the ticket is resolved. This of course requires good hygiene of tickets as tickets which are open for a long time can create extended periods of escalated access. Contextual analysis is required to identify the exact mechanisms here, but in most organisations masked data should be able to cover most scenarios so that access to confidential data should be very limited. Root access to production systems should be very limited in any case as automation takes over traditional tasks that used to require such access hence the risk is more limited in a DevOps world. And automation also increase the auditability of changes as everything gets logged.
Summary of Segregation of Duties in a DevOps world
Hopefully this gives you a few ideas on how to approach segregation of duties in the DevOps world. Keep in mind that you achieve the best results by bringing the auditors and governance stakeholders to the table early and explore how to make their life better with these approaches as well. This should be a win-win situation, and in my experience it usually is, once you get to the bottom of what is actually the concern to address.